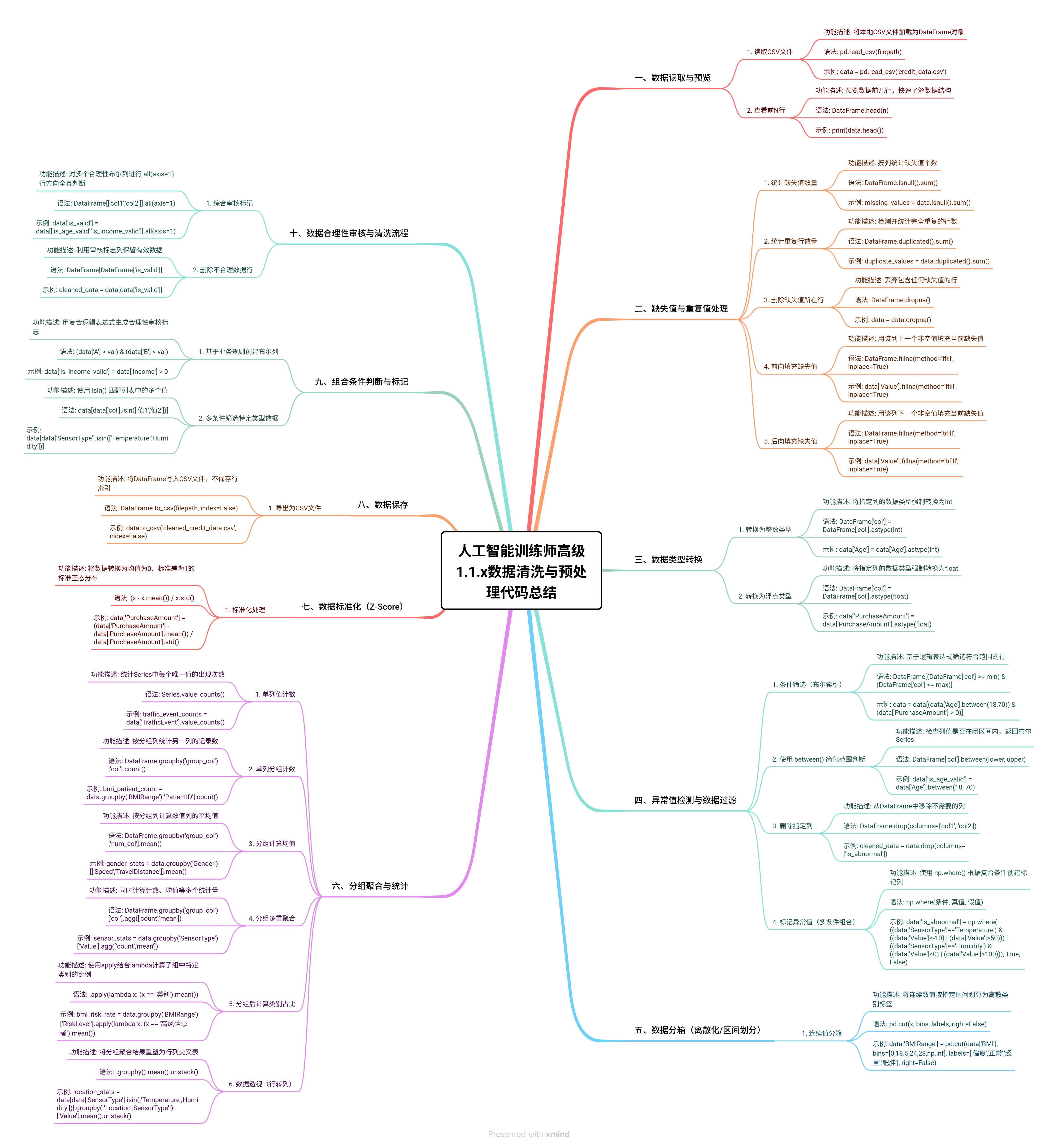
以下将 1.1.1 至 1.1.5 五个 Notebook 中的空缺代码补全要点,按数据处理领域分类,以表格形式呈现,每项包含功能描述、语法和使用示例。
一、数据读取与预览
| 功能 |
描述 |
语法 |
示例 |
| 读取 CSV 文件 |
将本地 CSV 文件加载为 DataFrame 对象 |
pd.read_csv(filepath) |
data = pd.read_csv('credit_data.csv') |
| 查看前 N 行 |
预览数据前几行,快速了解数据结构 |
DataFrame.head(n) |
print(data.head()) |
二、缺失值与重复值处理
| 功能 |
描述 |
语法 |
示例 |
| 统计缺失值数量 |
按列统计缺失值个数 |
DataFrame.isnull().sum() |
missing_values = data.isnull().sum() |
| 统计重复行数量 |
检测并统计完全重复的行数 |
DataFrame.duplicated().sum() |
duplicate_values = data.duplicated().sum() |
| 删除缺失值所在行 |
丢弃包含任何缺失值的行 |
DataFrame.dropna() |
data = data.dropna() |
| 前向填充缺失值 |
用该列上一个非空值填充当前缺失值 |
DataFrame.fillna(method='ffill', inplace=True) |
data['Value'].fillna(method='ffill', inplace=True) |
| 后向填充缺失值 |
用该列下一个非空值填充当前缺失值 |
DataFrame.fillna(method='bfill', inplace=True) |
data['Value'].fillna(method='bfill', inplace=True) |
三、数据类型转换
| 功能 |
描述 |
语法 |
示例 |
| 转换为整数类型 |
将指定列的数据类型强制转换为 int |
DataFrame['col'] = DataFrame['col'].astype(int) |
data['Age'] = data['Age'].astype(int) |
| 转换为浮点类型 |
将指定列的数据类型强制转换为 float |
DataFrame['col'] = DataFrame['col'].astype(float) |
data['PurchaseAmount'] = data['PurchaseAmount'].astype(float) |
四、异常值检测与数据过滤
| 功能 |
描述 |
语法 |
示例 |
| 条件筛选(布尔索引) |
基于逻辑表达式筛选符合范围的行 |
DataFrame[(DataFrame['col'] >= min) & (DataFrame['col'] <= max)] |
data = data[(data['Age'].between(18,70)) & (data['PurchaseAmount'] > 0)] |
使用 between() 简化范围判断 |
检查列值是否在闭区间内,返回布尔 Series |
DataFrame['col'].between(lower, upper) |
data['is_age_valid'] = data['Age'].between(18, 70) |
| 删除指定列 |
从 DataFrame 中移除不需要的列 |
DataFrame.drop(columns=['col1', 'col2']) |
cleaned_data = data.drop(columns=['is_abnormal']) |
| 标记异常值(多条件组合) |
使用 np.where() 根据复合条件创建标记列 |
np.where(条件, 真值, 假值) |
data['is_abnormal'] = np.where( ((data['SensorType']=='Temperature') & ((data['Value']<-10) \| (data['Value']>50))) \| ((data['SensorType']=='Humidity') & ((data['Value']<0) \| (data['Value']>100))), True, False) |
五、数据分箱(离散化/区间划分)
| 功能 |
描述 |
语法 |
示例 |
| 连续值分箱 |
将连续数值按指定区间划分为离散类别标签 |
pd.cut(x, bins, labels, right=False) |
data['BMIRange'] = pd.cut(data['BMI'], bins=[0,18.5,24,28,np.inf], labels=['偏瘦','正常','超重','肥胖'], right=False) |
六、分组聚合与统计
| 功能 |
描述 |
语法 |
示例 |
| 单列值计数 |
统计 Series 中每个唯一值的出现次数 |
Series.value_counts() |
traffic_event_counts = data['TrafficEvent'].value_counts() |
| 单列分组计数 |
按分组列统计另一列的记录数 |
DataFrame.groupby('group_col')['col'].count() |
bmi_patient_count = data.groupby('BMIRange')['PatientID'].count() |
| 分组计算均值 |
按分组列计算数值列的平均值 |
DataFrame.groupby('group_col')['num_col'].mean() |
gender_stats = data.groupby('Gender')[['Speed','TravelDistance']].mean() |
| 分组多重聚合 |
同时计算计数、均值等多个统计量 |
DataFrame.groupby('group_col')['col'].agg(['count','mean']) |
sensor_stats = data.groupby('SensorType')['Value'].agg(['count','mean']) |
| 分组后计算类别占比 |
使用 apply 结合 lambda 计算子组中特定类别的比例 |
.apply(lambda x: (x == '类别').mean()) |
bmi_risk_rate = data.groupby('BMIRange')['RiskLevel'].apply(lambda x: (x == '高风险患者').mean()) |
| 数据透视(行转列) |
将分组聚合结果重塑为行列交叉表 |
.groupby().mean().unstack() |
location_stats = data[data['SensorType'].isin(['Temperature','Humidity'])].groupby(['Location','SensorType'])['Value'].mean().unstack() |
七、数据标准化(Z-Score)
| 功能 |
描述 |
语法 |
示例 |
| 标准化处理 |
将数据转换为均值为 0、标准差为 1 的标准正态分布 |
(x - x.mean()) / x.std() |
data['PurchaseAmount'] = (data['PurchaseAmount'] - data['PurchaseAmount'].mean()) / data['PurchaseAmount'].std() |
八、数据保存
| 功能 |
描述 |
语法 |
示例 |
| 导出为 CSV 文件 |
将 DataFrame 写入 CSV 文件,不保存行索引 |
DataFrame.to_csv(filepath, index=False) |
data.to_csv('cleaned_credit_data.csv', index=False) |
九、组合条件判断与标记
| 功能 |
描述 |
语法 |
示例 |
| 基于业务规则创建布尔列 |
用复合逻辑表达式生成合理性审核标志 |
(data['A'] > val) & (data['B'] < val) |
data['is_income_valid'] = data['Income'] > 0 |
| 多条件筛选筛选特定类型数据 |
使用 isin() 匹配列表中的多个值 |
data[data['col'].isin(['值1','值2'])] |
data[data['SensorType'].isin(['Temperature','Humidity'])] |
十、数据合理性审核与清洗流程
| 功能 |
描述 |
语法 |
示例 |
| 综合审核标记 |
对多个合理性布尔列进行 all(axis=1) 行方向全真判断 |
DataFrame[['col1','col2']].all(axis=1) |
data['is_valid'] = data[['is_age_valid','is_income_valid']].all(axis=1) |
| 删除不合理数据行 |
利用审核标志列保留有效数据 |
DataFrame[DataFrame['is_valid']] |
cleaned_data = data[data['is_valid']] |